Autoscaling Won't Save You from Overload
How load shedding and admission control keep instances responsive by rejecting excess traffic early

Imagine two ways your system can get overloaded.
In the first, demand spikes suddenly.
For example:
a retry storm builds up
traffic returns after an outage and the cluster has already scaled down
an external event triggers a burst of requests in a matter of seconds
In the second, incoming traffic stays roughly the same, but each instance’s real capacity drops: it can sustain fewer requests per second, or fewer concurrent requests, before becoming overloaded.
For example:
a dependency gets slower
network latency to a dependency increases
contention appears around an internal resource, such as CPU, threads, or a connection pool
In systems with autoscaling, this does not necessarily lead to overload. If the policies are well configured, the cluster can grow and absorb part of the problem.
But that is not always enough. Scaling takes time, sometimes reacts to lagging or indirect signals, and can arrive too late for a burst. And if the bottleneck is a slow dependency or some other shared resource, adding more replicas does not necessarily fix anything.
The key question is not whether the cluster eventually scales. The key question is what happens in the interval where an instance starts receiving more work than it can process without degrading.
In the first case, demand changed: clients are pushing more traffic. In the second case, capacity changed: each instance can sustain less work before becoming overloaded.
In both cases, the outcome can be the same: effective demand exceeds the effective capacity of at least some instances. Those instances become overloaded, latency spikes, and eventually they start failing.
In both cases, the outcome can be the same: at least some instances start receiving more load than they can sustain without degrading. Those instances become overloaded, latency spikes, and eventually they start failing.
And that is not the whole story.
A few instances usually fail first or get removed from the load balancer. The load they were handling does not disappear: it shifts to the instances that remain, and part of it often comes back as retries, pushing the load per instance even higher until more of them degrade and fail too.
You get a cycle like this:
overload → degradation → failure → redistribution → more overload
And when you try to recover, you fall over again.
Fixed Limits Are Not Enough
A common response is to add a rate limiter.
The idea sounds reasonable: measure how much traffic an instance can handle, define a limit, and reject anything above it. That can help, but it has an important problem: real capacity is not fixed.
You can run load tests and find a saturation point at X requests per second. But in production, that number changes all the time. If a dependency gets slower, each request takes longer, holds resources for longer, and the number of requests you can process drops. The system may still be receiving the same traffic, but its effective capacity is now lower.
Put differently: if each request takes longer, you need more requests in flight to sustain the same throughput. That increases pressure on every shared resource. This is the same intuition behind Little’s Law, where concurrency rises as latency rises for the same traffic level.
The rate limiter is still using the same number, even though the system can no longer sustain it. At that point, it may stop protecting you.
What you need is not just traffic limiting in the abstract.
You need to decide how much work to admit based on the system’s actual capacity:
reject excess traffic while continuing to process the work you can still handle without degrading
you do not want to accept everything, because you will collapse
you do not want to reject too much, because you would waste capacity
That is one form of load shedding.
The goal is not to maximize throughput. The goal is to keep the instance from entering saturation: the point where everything starts getting worse at once.
The Right Question
Instead of asking, “How many requests per second can I accept?”, the right question is, “How much concurrent work can this instance sustain without degrading?”
That is what you want to control and protect, more than request rate.
When an instance becomes overloaded, the problem is not just how many requests arrive per second. The problem is how many are competing at the same time for CPU, memory, connections, workers, or a slow dependency.
Concurrency is often a good proxy for load, though not always. What matters is identifying which resource saturates first in your system.
One simple way to protect that capacity is to put a limit on in-flight requests. There are more sophisticated ways to control load, but in-flight requests are often simple and effective enough in practice.
Up to that point, the instance keeps processing normally. If a short burst arrives, you can still absorb part of it with a queue for pending requests.
But that queue has to be bounded. It is not there to hide saturation. It is there to absorb short-lived variation without letting the instance collapse.
And you also need a time limit. If a request has already been waiting too long, keeping it around no longer helps. It only adds latency, consumes resources, and makes the situation worse. At that point, it makes more sense to cancel or reject it.
The result is straightforward:
the instance processes up to a level of concurrency it can actually sustain
it keeps a small queue for pending requests to absorb short bursts
it drops the excess once waiting no longer makes sense
That changes something important: concurrency stops being dictated by clients and starts being dictated by the instance’s capacity.
Put another way, arrival rate and processing rate are no longer fully coupled. Requests can still arrive via push, but once admitted, the system processes them at the pace it can actually sustain.
That creates a simple form of backpressure. It is not exactly the same thing as load shedding: backpressure tries to reduce how much work keeps flowing in, while load shedding explicitly decides what work to leave out.
Instead of accepting everything and degrading, you accept up to a limit and reject or expire the excess.
During recovery from an outage or a retry storm, that makes a real difference:
some traffic gets rejected
but the instance can keep serving the part it can still process
and it buys time for the system to recover, for the cluster to scale, or for traffic to stabilize
This becomes easier to see in a simple single-instance load test. Same basic setup, same kind of traffic, one major difference: whether the instance is protected by admission control and load shedding or not.
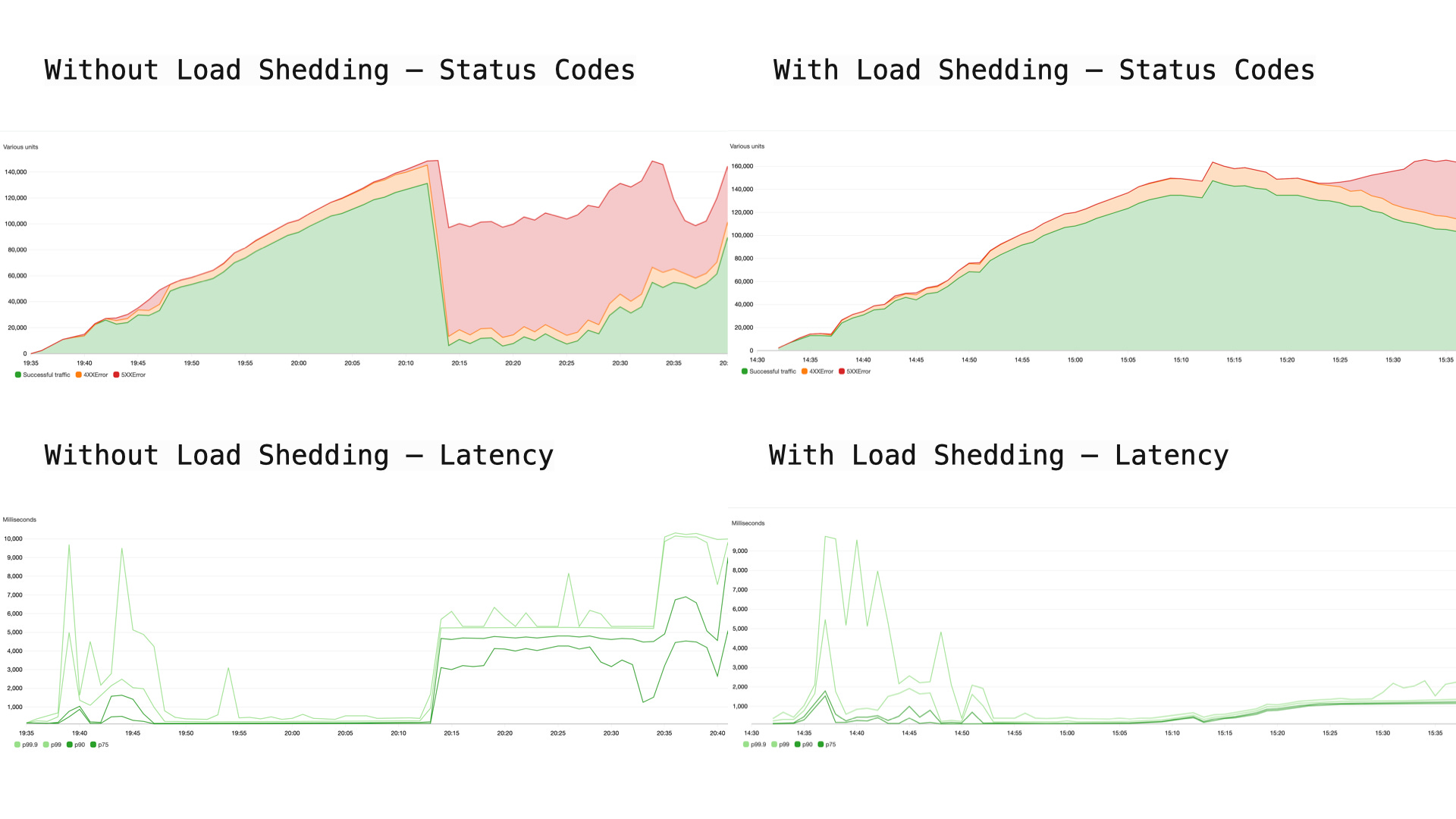
Single-instance load test before and after adding load shedding in front of the service. Without admission control, overload turns into rising latency and widespread failures. With load shedding, excess requests are rejected earlier, but latency stays bounded and the instance keeps serving the traffic it can still handle.
Besides limiting in-flight work, it also usually makes sense to limit how many incoming connections you are willing to accept.
Otherwise, you can overload the instance before request processing even begins.
Where to Apply It
You can implement this control inside the application.
For example:
limit in-flight requests
enqueue pending requests into a bounded internal queue
cancel or reject requests that have already waited too long
That already improves behavior a lot under load. But it has an important limitation.
By the time a request reaches the application, it has already consumed some of the resources you were trying to protect:
an open connection
memory
threads or event loops
parsing, routing, and other work that already happened
In other words: you are still rejecting, but you are rejecting late.
That is why, if you can, it often makes sense to move this control in front of the application.
For example, into a reverse proxy in front of the app. There, you can apply the same basic idea:
limit how much traffic you admit
keep a small queue for pending requests
decide when a request has already waited too long
But with one important difference:
you are controlling admission before the traffic touches the application
That changes the behavior quite a bit:
rejecting early is usually cheaper than rejecting inside the app
the mechanism becomes more reliable, because it can still protect you even after the application has already started degrading
the solution becomes much more reusable across services, regardless of the tech stack
You do not need a complex distributed mechanism to get started. Quite often, a simple reverse proxy with a per-target concurrency limit, a queue for pending requests, and a timeout is enough.
What It Looks Like in Practice
The good news is that this usually does not require inventing a brand-new mechanism from scratch.
In many stacks, you already have building blocks that get you pretty close:
concurrency limits or in-flight request limits
bounded queues for pending requests
wait timeouts or deadlines
In some stacks, the same ideas show up inside more general mechanisms such as circuit breakers, overload controls, or QoS policies.
Not all of them implement exactly the same pattern.
Some expose an explicit queue with a timeout. Others give you concurrency limits, connection backlog controls, or broader mechanisms that shape admission more indirectly.
But what matters is not the exact tool, nor what your stack happens to call it.
What matters is the policy:
do not admit more work than you can still process in time
If you already have a proxy, web server, or framework that lets you approximate that, that is often enough to get started.
What Still Can Break Anyway
Up to this point, everything sounds fairly reasonable.
You limit how much work gets in, reject what you cannot process, and in theory that should be enough.
In practice, there are still a few details that can break the system if you do not account for them.
1. Health Checks
If the proxy starts rejecting requests when it is overloaded, what happens to the health checks?
If you treat them like any other request, they will get rejected too.
And then you get another loop:
the instance is overloaded, but alive
it starts rejecting health checks
the load balancer marks it unhealthy
it stops sending traffic there
That traffic does not disappear.
It moves to other instances, which now receive more load, become overloaded, start rejecting health checks, and also get removed.
You end up here:
overload → health checks fail → instances get removed → more load on the remaining ones → more overload
The fix is simple, but not always obvious:
separate health check traffic from everything else
For example:
a path that does not go through the same admission control
a dedicated connection pool
reserved budget for control traffic
The point is that an overloaded instance should still be able to say:
I am alive, I am just limited
In practice, one common way to do this is to expose health checks on a separate port, so they do not compete with normal traffic on the exact same listener and admission path.
The broader principle is that not all traffic deserves the same treatment, and not all of it should share the same budget.
2. Connection Churn
Another common problem is connection churn.
And with HTTPS, that cost can be especially high: a new connection needs not only the TCP handshake, but also the TLS negotiation. On networks with non-trivial latency, that can easily add tens or even hundreds of milliseconds before the request even starts being processed.
In scenarios with aggressive retries or timeouts:
connections are opened and closed constantly
SYN traffic grows
operating-system limits start to matter, such as sockets or ephemeral ports
You can end up overloading the instance without ever hitting your in-flight request limit.
This happens underneath the application.
And when it does, you are back in the worst case:
connections cannot be established
requests never arrive
behavior becomes hard to observe
Here again, early control helps:
limit incoming connections
reuse connections with keep-alive
avoid unnecessary churn
3. When Traffic Is Too Large
There is a more extreme case.
Sometimes traffic is so high that it no longer makes sense to even try to process part of it.
For example:
a severe retry storm
an external event that triggers massive traffic
a system coming back from an outage while every client retries at once
In those cases, even the proxy can come under pressure.
One useful strategy is to have an escape hatch: a cheap way to drop traffic before it reaches the real instances.
One simple way to do that, and something you do see in practice, is to reserve a target group in the load balancer with no real backends registered behind it.
Under normal conditions, it is not part of the traffic path. But if you need to take pressure off the real instances, you can redirect part of the traffic toward that target, which in practice acts like a black hole.
It is a crude but effective mechanism: it does not distinguish between different kinds of traffic, and it does not let you apply fine-grained policies, but it can still be enough to keep the whole system from collapsing.
When you detect that the system is completely overwhelmed:
redirect or discard traffic directly
protect the real instances
keep the whole cluster from collapsing
It is not elegant.
But it is better than a cascading failure.
Choosing How to Degrade
Load shedding is not magic. It does not give you infinite capacity. It does not eliminate the need to reject requests. It does not turn an overwhelmed system into a healthy one.
What it does do is help you avoid a much worse decision: continuing to accept work when you can no longer process it without breaking yourself. Without admission control, the system tries to do everything. Latency piles up, resources get retained, degradation spreads, and the system eventually collapses.
With load shedding, the system stops pretending it can handle everything. It rejects part of the traffic to protect what it can still process. That difference is often what separates a cascading cluster-wide failure from a system that stays up long enough for scaling and recovery to work.
In the previous post, I argued that resilience is ultimately about choosing what breaks first. Here, that becomes very concrete: it is better to reject part of the traffic than to lose the entire system.
Because when more traffic arrives than you can actually handle, the real question is not how much you accept, but whether you can keep the system running while rejecting the rest.
Further Reading
Using load shedding to avoid overload – AWS Builders Library.
Avoiding overload in distributed systems by putting the smaller service in control – AWS Builders Library.
Timeouts, retries, and backoff with jitter – AWS Builders Library.
Addressing Cascading Failures – Google SRE Book.
Overload Manager – Envoy documentation.